Introducing Aurora
- Jalaj Upadhyay
- 3 days ago
- 3 min read
This blog explores a critical element of modern Transformer architecture, highlighting how it can be viewed as a rediscovery of 20th-century matrix analysis. We’ll conclude with concrete results to demonstrate its impact. Together with LaserTune and some other optimizations, this innovation allows a dramatic increase in inference speed for longer context length. The other optimizations are not the topic of this blog (stay tuned for it). This blog mainly covers our improvement over Softmax.
To begin, let's consider the ultimate goal of deep learning models: to mimic the human brain. While this applies to all kinds of datasets (text, vision, speech, etc.), we will focus on text for simplicity. A core task of any model is to take a piece of text (whether a book, paragraph, or sentence) and predict the next word. This post will focus on self-attention, a key component in this process.
When you read a word like “bark,” what associations come to mind? A dog lover might think of a dog’s bark, while a nature enthusiast may think of tree bark, and a chocolate lover might imagine bark-like chocolate pieces. These associations vary depending on personal experiences. Mimicking this flexibility in a machine is a challenge, but let's assume that the brain maps each word to a high-dimensional vector, and different individuals process this vector in different subspaces based on their biases. This simplified view offers a foundational understanding of Transformer-like models, particularly self-attention.
Softmax and its Challenges
A bottleneck in Transformer architecture is the Softmax function, which introduces non-linearity and complicates self-attention calculations. At a high level, softmax converts a vector of raw scores (logits) into a probability distribution. However, when applied to large sequences in models like Transformers, it introduces quadratic time complexity due to the need to compute pairwise interactions between all tokens in the sequence. This becomes computationally expensive as sequence length increases.
The quadratic time complexity of Softmax directly impacts training time and is particularly problematic for models that handle long sequences, such as those in NLP tasks. Additionally, Softmax’s space requirements on resource-constrained devices can cause memory bottlenecks, leading to page faults and delays due to data fetching from storage.
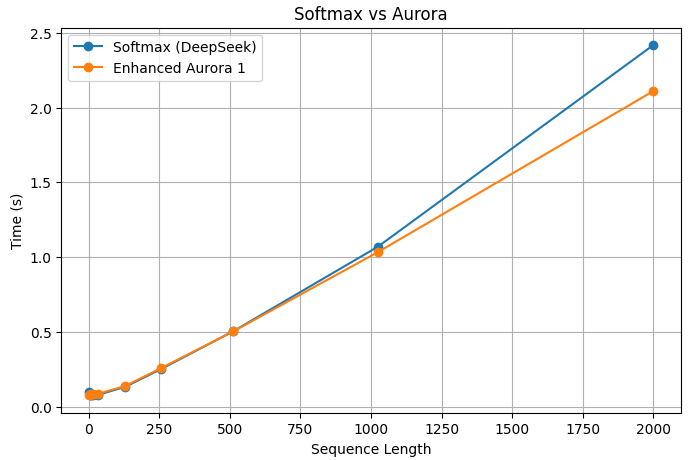
Aurora addresses both issues. It reduces computational time to near linear complexity with respect to sequence length and lowers space requirements compared to traditional Softmax. The plot below demonstrates the performance improvement of Aurora over a highly optimized Softmax implementation in PyTorch, tested on the DeepSeek Coder 1.3B instruct model and Llama 3.2 1B instruct model. Similar gains are observed with larger models as well.
As we can see in the plots, while the curvature of the run time of Softmax is quadratic in the sequence length (a more parabolic shape), that of Aurora is almost linear. Consequently, when the context length grows longer, we see a larger factor improvement, which, when combined with LaserTune, gives a dramatic improvement in the inference speed.

Implications of Aurora
Aurora’s benefits extend to various domains:
NLP Models: Transformers like GPT and BERT, which process long sequences, can train and infer much faster due to the reduction in time complexity.
Real-Time Systems: Aurora improves the efficiency of real-time systems such as recommendation engines and autonomous vehicles, enabling quicker decisions based on large datasets.
Resource-Constrained Environments: Edge devices and low-power applications can now deploy sophisticated machine-learning models without overwhelming computational resources.
Furthermore, Aurora is compatible with popular machine learning frameworks (TensorFlow, PyTorch), making it easy to integrate into existing models and offering a seamless optimization that can be incorporated into systems like LaserTune.
Conclusion
Aurora represents a paradigm shift in optimizing Softmax for machine learning. By reducing Softmax’s time complexity from quadratic to near-linear, Aurora paves the way for more efficient models capable of handling larger datasets, longer sequences, and real-time applications. This is a significant step forward for deep learning, especially in fields like NLP, computer vision, and autonomous systems, where speed and scalability are increasingly critical.
As machine learning continues to evolve, optimizations like Aurora will likely become the standard, helping to not only improve accuracy but also drive efficiency. Aurora is leading the way toward making this future a reality.
Comments